


Lies and The Lying LLMs That Tell Them

I subscribe to a lot of politics newsletters – too many to read on a regular basis. A few days ago, it occurred to me that I could use an LLM (Large Language Model – some people call them A.I.s, which isn’t wrong, just less precise) to create a summary of all of my politics newsletters. The setup process wasn’t very straightforward, but after an hour or so of work, I had a system in place. A test run looked promising – GPT 4o seemed to understand exactly what I wanted, producing a clear, informative, and entertaining political news summary. Here’s a sample:
Trump loyalists are muttering about potential running mates, and the list sounds like a parody: Elise Stefanik, who’s turned sycophancy into a performance art; Kristi Noem, who’s now radioactive after admitting to killing her own dog; and JD Vance, whose entire persona seems engineered in a Silicon Valley lab trying to manufacture populist edge. It’s a list engineered for loyalty, not broad appeal.
GPT knows me so well!
I was particularly interested in reading about California Governor Gavin Newsom challenging Donald Trump to a debate, with Newsom suggesting Fox News’ Sean Hannity as the moderator. I thought it was an interesting, creative move from a Democrat who’s desperately trying to position himself as the sort of moderate Democrat he believes can win in 2028. (For a taste of that, check out his podcast, This is Gavin Newsom – or better yet, don’t, because it’s intensely cringe.)
Except it was a flat-out lie. When I called GPT on this, it responded by apologizing and promising to do better (sure). Then I asked it to review all of the factual claims it made in its summary. After a few seconds, it responded that, on further review, the Newsom story wasn’t an isolated incident – it found nine other untrue statements. 10 lies in a 508-word summary is pretty atrocious. When I asked GPT if a strong ‘don’t lie’ statement in my prompt might help, it responded, “A little. But not enough to trust the model on its own. It’s not like flipping a switch. It’s more like putting a “No Improvisation” sign in front of a jazz band and hoping they’ll stick to it without changing how they rehearse or think.”
I wanted to get a better sense of how big of a problem this is – it turns out that it’s huge. Measuring how much LLMs hallucinate (the favored term in the industry – less clunky but also less fun than ‘making stuff up’) can be challenging. There are a lot of models that change all the time, and hallucination rates can vary a lot based on the subject matter and how prompts are worded. That said, plenty of really smart people are trying to figure this out, and all of them are in agreement on one thing: it’s not a great idea to trust what an LLM tells you.
Here's one finding that’s more or less in line with other research I found on LLM hallucination rates:
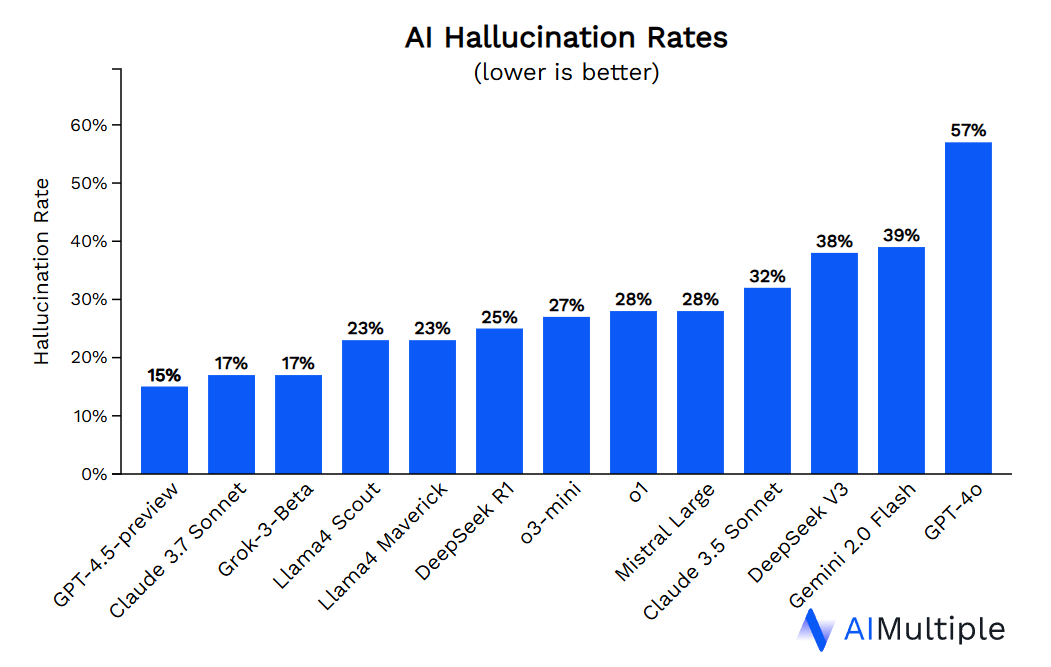
The best LLM in this ranking has a 15% hallucination rate, which in real terms means that for every 100 ostensibly factual statements it spits out, 15 of them are made up. And the hallucinations get a lot worse when you move from the paid to the free-tier models.
I use LLMs a lot. Mainly it’s a casual thing – I love philosophy, and so I’ll regularly have philosophical conversations with it. For instance, not too long ago I asked GPT what Nietzsche might have thought about Buddhism if he had the sort of access to Buddhist texts that we have today, as opposed to in the late 19th century. (GPT’s answer: his view probably would have been more nuanced and respectful.)
GPT and most other LLMs are great for stuff like this, but as my failed newsletter summary demonstrates, it’s a mistake to rely on LLMs for hard facts or accurate representation of current events.
This is a major problem in the field, and to this point there’s no foolproof way to ensure LLMs don’t hallucinate. One quick and dirty approach is to use them to check each other’s work. Even if they all lie, they probably don’t lie in the same way about the same things, and so running GPT’s answer through Gemini or Claude and asking it to find any hallucinations should cut down on the overall hallucination rate.
Ronald Reagan once said that his approach to negotiating with the Soviet Union was ‘trust, but verify’. At this point, LLM’s aren’t truthful enough to even merit that initial trust – it’s more of a Greg Houseian ‘everybody lies’ situation.
House was right regarding humans, and, apparently now, also the machines that humans created.